1. Data Engineering Fundamentals
Q1. What is Data Engineering?
Answer:
Data Engineering focuses on designing, building, and maintaining systems that collect, store, process, and distribute data for analytics, reporting, AI, and machine learning.
Key Responsibilities
- Data ingestion
- ETL/ELT pipeline development
- Data warehousing
- Data quality management
- Data governance
- Real-time data streaming
Q2. Difference Between ETL and ELT?
| ETL | ELT |
|---|---|
| Extract → Transform → Load | Extract → Load → Transform |
| Transformation before loading | Transformation after loading |
| Suitable for traditional warehouses | Suitable for cloud warehouses |
| Less scalable | Highly scalable |
Examples:
- ETL: Informatica, SSIS
- ELT: Snowflake, BigQuery, Redshift
Q3. What is a Data Lake?
A centralized repository that stores structured, semi-structured, and unstructured data.
Benefits:
- Low cost storage
- Supports AI/ML workloads
- Stores raw data
Examples:
- AWS S3
- Azure Data Lake
- Google Cloud Storage
Q4. What is a Data Warehouse?
A system optimized for analytical queries and reporting.
Examples:
- Snowflake
- Amazon Redshift
- Google BigQuery
2. Big Data Concepts
Q5. What are the 5 Vs of Big Data?
- Volume
- Velocity
- Variety
- Veracity
- Value
Q6. What is Apache Hadoop?
An open-source framework for distributed storage and processing of large datasets.
Components:
- HDFS
- YARN
- MapReduce
- Hive
Q7. What is Apache Spark?
A distributed processing engine used for:
- Batch processing
- Streaming
- Machine Learning
- Graph Analytics
Advantages Over Hadoop
- In-memory processing
- Faster execution
- Better ML support
3. Machine Learning Fundamentals
Q8. What is Machine Learning?
Machine Learning enables systems to learn from data without explicit programming.
Types:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Q9. Difference Between AI, ML, and Deep Learning?
| AI | ML | Deep Learning |
|---|---|---|
| Broad field | Subset of AI | Subset of ML |
| Mimics intelligence | Learns patterns | Uses neural networks |
| Rule-based + learning | Data-driven | Large-scale learning |
Q10. What is Supervised Learning?
Training using labeled data.
Examples:
- House price prediction
- Spam detection
- Fraud detection
Algorithms:
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
Q11. What is Unsupervised Learning?
Training using unlabeled data.
Examples:
- Customer segmentation
- Anomaly detection
Algorithms:
- K-Means
- DBSCAN
- Hierarchical Clustering
Q12. What is Reinforcement Learning?
An agent learns by interacting with an environment and receiving rewards.
Examples:
- Robotics
- Autonomous Vehicles
- Game AI
4. Machine Learning Algorithms
Q13. What is Linear Regression?
Used to predict continuous values.
y=mx+b
m
b
Example:
Predicting house prices.
Q14. What is Logistic Regression?
Used for classification problems.
Examples:
- Spam vs Not Spam
- Fraud vs Genuine
Q15. What is Random Forest?
An ensemble algorithm combining multiple decision trees.
Advantages:
- High accuracy
- Reduces overfitting
- Handles large datasets
Q16. What is XGBoost?
A gradient boosting algorithm widely used in machine learning competitions.
Advantages:
- High performance
- Fast training
- Handles missing values
Q17. What is Overfitting?
Model learns training data too well and performs poorly on new data.
Solutions:
- Regularization
- More data
- Cross-validation
- Dropout
Q18. What is Underfitting?
Model is too simple and cannot capture patterns.
Solutions:
- Increase complexity
- Add features
- More training
5. Feature Engineering
Q19. What is Feature Engineering?
Process of creating useful input variables from raw data.
Examples:
- Date extraction
- Aggregations
- Encoding categories
Q20. What is One-Hot Encoding?
Converts categorical variables into binary vectors.
Example:
| Color | Red | Blue | Green |
|---|---|---|---|
| Red | 1 | 0 | 0 |
Q21. What is Feature Scaling?
Normalizes numerical features.
Techniques:
- Min-Max Scaling
- Standardization
Standardization:
z=σx−μ
x
μ
σ
z=σx−μ≈1.2
Φ(z)≈88.5%
6. Model Evaluation
Q22. What is a Confusion Matrix?
| Actual / Predicted | Positive | Negative |
|---|---|---|
| Positive | TP | FN |
| Negative | FP | TN |
Q23. Precision vs Recall?
Precision
= Correct Positive Predictions / Total Predicted Positives
Recall
= Correct Positive Predictions / Total Actual Positives
Use:
- Precision → Fraud Detection
- Recall → Disease Detection
Q24. What is F1 Score?
Harmonic mean of Precision and Recall.
F1=2⋅Precision+RecallPrecision⋅Recall
Q25. What is ROC-AUC?
Measures classification performance across different thresholds.
Higher AUC = Better model.
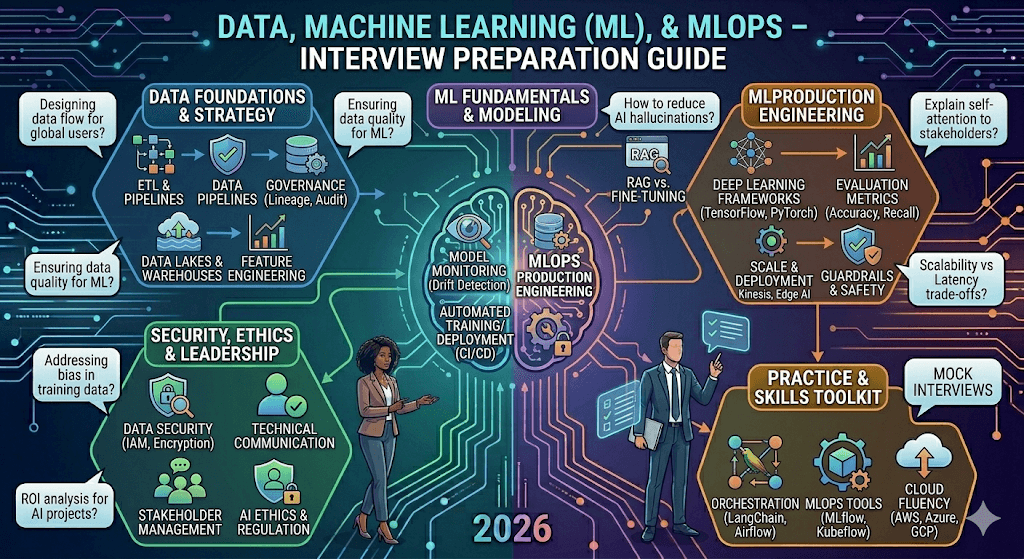
7. MLOps Fundamentals
Q26. What is MLOps?
MLOps (Machine Learning Operations) is the practice of applying DevOps principles to ML systems.
Goals:
- Automation
- Reproducibility
- Monitoring
- Scalability
- Governance
Q27. Why is MLOps Important?
Without MLOps:
- Manual deployments
- Model drift
- Inconsistent environments
- Difficult rollback
With MLOps:
- Automated pipelines
- CI/CD for ML
- Faster deployments
- Better monitoring
Q28. MLOps Lifecycle
- Data Collection
- Data Validation
- Feature Engineering
- Model Training
- Model Validation
- Model Deployment
- Monitoring
- Retraining
Q29. What is Model Drift?
When production data differs from training data, causing performance degradation.
Types:
- Data Drift
- Concept Drift
Q30. What is Feature Store?
Central repository for storing and serving ML features.
Examples:
- Feast
- Tecton
Benefits:
- Reusability
- Consistency
- Faster model development
Q31. What is Model Registry?
Repository for managing ML model versions.
Examples:
- MLflow
- Weights & Biases
Q32. What is CI/CD for ML?
CI:
- Code validation
- Unit testing
- Data validation
CD:
- Automated deployment
- Canary releases
- Rollback
Tools:
- GitHub Actions
- GitLab
- Jenkins
8. ML System Design Interview Questions
Q33. Design a Recommendation Engine
Architecture:
- User Activity Data
- Data Lake
- Feature Store
- Training Pipeline
- Model Registry
- Real-Time Inference API
Examples:
- Movie recommendations
- Product recommendations
Q34. Design a Fraud Detection System
Components:
- Streaming ingestion
- Feature computation
- Real-time scoring
- Alerting system
Tools:
- Kafka
- Spark Streaming
- ML Models
- Dashboard
Q35. Design a Real-Time Prediction Platform
Components:
- API Gateway
- Feature Store
- Model Server
- Monitoring
Latency Goal:
<100ms
9. Scenario-Based Interview Questions
Q36. A model accuracy drops after deployment. What will you do?
Answer:
- Check data drift
- Validate incoming features
- Review monitoring metrics
- Compare training vs production distributions
- Retrain if required
Q37. How do you handle imbalanced datasets?
Methods:
- SMOTE
- Oversampling
- Undersampling
- Class Weights
- Anomaly Detection
Q38. How do you reduce ML training cost?
- Spot Instances
- Distributed Training
- Feature Selection
- Model Compression
- Efficient Data Pipelines
10. Frequently Asked Architect-Level Questions
Q39. Difference Between Data Engineer, ML Engineer, and MLOps Engineer?
| Role | Responsibility |
|---|---|
| Data Engineer | Data pipelines |
| ML Engineer | Model development |
| MLOps Engineer | Deployment & operations |
Q40. What does an AI/ML Architect do?
Responsibilities:
- Define AI strategy
- Select architecture patterns
- Design MLOps platforms
- Establish governance
- Ensure scalability and security
- Lead AI transformation initiatives
Top Tools to Know for 2026
Data Engineering
- Apache Spark
- Kafka
- Airflow
- dbt
- Snowflake
- Databricks
Machine Learning
- Scikit-learn
- TensorFlow
- PyTorch
- XGBoost
MLOps
- MLflow
- Kubeflow
- Feast
- Weights & Biases
- Docker
- Kubernetes
Cloud AI Platforms
- Amazon Web Services SageMaker
- Microsoft Azure Machine Learning
- Google Cloud Vertex AI
These are the core Data Engineering, Machine Learning, and MLOps interview topics commonly covered for Senior Data Engineer, ML Engineer, AI Architect, Data Architect, Solution Architect, and Enterprise Architect roles.
Data, ML, and MLOps form the core technical backbone of modern AI/ML systems. They represent the end-to-end lifecycle of building, deploying, and maintaining intelligent applications.
1. Data (Data Engineering + Data Science Foundations)
This is the foundation. Without good data, nothing else works.
Key Areas:
- Data Ingestion: Collecting data from sources (databases, APIs, streams, logs, sensors).
- Data Storage: Data lakes (S3, GCS), warehouses (Snowflake, BigQuery, Redshift), lakeshouses (Databricks, Iceberg).
- Data Processing: ETL/ELT pipelines, batch vs streaming (Spark, Flink, Kafka, Airflow, dbt).
- Data Quality & Governance: Validation, lineage, cataloging (Great Expectations, Amundsen, DataHub).
- Feature Engineering & Exploration: Pandas, Spark, Polars; statistical analysis.
Modern Stack (2026):
- Orchestration: Dagster, Prefect, Airflow
- Compute: Spark, Ray, Dask
- Storage: Iceberg + S3/GCS + Trino/Presto for querying
- Real-time: Kafka + Flink + Redis
Skills to focus on:
- SQL mastery + Python (or Scala/Java for heavy data eng)
- Distributed systems concepts
- Data modeling (dimensional + data mesh)
2. Machine Learning (Modeling & Experimentation)
This is where you turn data into predictions, decisions, or generations.
Core Concepts:
- Supervised, Unsupervised, Reinforcement Learning
- Classical ML vs Deep Learning
- Evaluation metrics, bias-variance, overfitting
- Experiment tracking (Weights & Biases, MLflow, Comet)
Current Practical Focus Areas (2026):
- Tabular Data — Still dominates enterprise: XGBoost, LightGBM, CatBoost, TabNet
- LLMs & Generative AI — Fine-tuning, RAG, agents, evaluation (Ragas, DeepEval)
- Computer Vision & Multimodal — Transformers, diffusion models
- MLOps-adjacent ML — Model compression, quantization, distillation, continual learning
Tools:
- Training: PyTorch (dominant), JAX (growing), Hugging Face
- Experimentation: Weights & Biases, ClearML
- Feature Store: Feast, Tecton, Hopsworks
3. MLOps (Productionizing ML)
This bridges the gap between data scientists and production systems. It’s the “DevOps for ML”.
Key Components:
- Model Training Orchestration — Kubeflow, Flyte, Metaflow, SageMaker Pipelines
- Model Registry & Versioning — MLflow, ClearML, Hugging Face Hub
- Model Deployment —
- Real-time: Seldon, KServe, BentoML, vLLM, TGI
- Batch: Spark, Airflow + model serving
- Monitoring & Observability —
- Performance drift, data drift (Evidently, WhyLabs, Arize)
- Model explainability (SHAP, LIME)
- CI/CD for ML — GitHub Actions + DVC + MLflow
- Infrastructure — Kubernetes + GPU operators, Ray Serve, Triton Inference Server
Mature MLOps Capabilities:
- Reproducible pipelines
- Automated retraining
- Shadow/canary deployments
- Feature store for consistency
- Cost monitoring (especially important with GPU/LLM inference)
- Governance & compliance (bias detection, audit trails)
Recommended Learning Path (2026)
Beginner → Intermediate:
- Solid Python + SQL
- Pandas + Scikit-learn + basic ML
- Deep Learning (fast.ai or Hugging Face course)
- Data engineering basics (dbt + Airflow)
Advanced:
- Build end-to-end project: Feature store → Training pipeline → Serving + monitoring
- Learn Kubernetes + Terraform basics
- Work with LLMs in production (RAG, evaluation, cost optimization)
Project Ideas:
- Real-time recommendation system
- Document intelligence platform with LLMs
- Predictive maintenance pipeline
- Autonomous agent with proper evaluation & safety rails
You’ve listed three interconnected pillars of modern data-driven engineering. Here’s a concise breakdown of each, how they relate, and why they matter together.
1. Data
The foundation. Without good data, nothing else works.
Key aspects:
- Collection: From apps, sensors, logs, user interactions
- Storage: Data warehouses (Snowflake, BigQuery), lakes (S3, ADLS), lakehouses
- Processing: Batch (Spark) & streaming (Kafka, Flink)
- Quality: Accuracy, completeness, freshness, consistency
- Governance: Lineage, catalogs, privacy (GDPR, CCPA), access control
Common pain point: “Garbage in, garbage out.” Data discovery and quality often consume 60–80% of a data scientist’s time.
2. ML (Machine Learning)
Turning data into predictions or insights.
Key aspects:
- Exploration & feature engineering: Understanding patterns, creating model inputs
- Model training: Choosing algorithms (XGBoost, neural nets), tuning hyperparameters
- Evaluation: Metrics (accuracy, recall, F1, AUC) and validation strategies
- Experiment tracking: Recording parameters, code, data versions, results (e.g., MLflow, Weights & Biases)
Challenge: Training works in a notebook, but scaling or reproducing it becomes messy without structure.
3. MLOps
Engineering discipline to operationalize ML at scale.
Borrows from DevOps but with ML-specific complexities (data, model decay, experiments).
Core components:
- Automated pipelines: Data validation → training → evaluation → model packaging
- Model registry & versioning: Storing, approving, and promoting models (staging → prod)
- CI/CD for models: Test code, data schemas, model quality before deployment
- Deployment patterns: Batch predictions, real-time API (REST, gRPC), edge
- Monitoring: Data drift, concept drift, model performance, latency, throughput
- Retraining triggers: Scheduled, performance-based, or data-driven
- Feature store: Centralized, versioned features serving both training and inference (e.g., Feast, Tecton)
Key realization: In production, your ML system is mostly data engineering and infrastructure — the model code is a small piece.
How they connect
text
Data → ML → MLOps
│ │ │
│ └───────┼─── Trains models
└───────────────┼─── Serves features to training & inference
└─── Monitors data & model healthExample flow:
- Data pipeline ingests raw clickstream events
- ML engineer trains a churn prediction model
- MLOps packages the model, deploys to a REST endpoint, monitors for drift, and triggers weekly retraining if data distribution changes.
Why separate these concepts?
| Role | Focus |
|---|---|
| Data Engineer | Reliable, scalable data pipelines (Data) |
| Data Scientist / ML Engineer | Model development, experiments (ML) |
| MLOps Engineer | Deployment, automation, monitoring, governance (MLOps) |
In small teams, one person wears multiple hats. In mature orgs, each is a specialty.
Quick maturity check
- Level 0: Ad-hoc notebook → handoff to eng (painful)
- Level 1: Scheduled training scripts, model saved to disk
- Level 2: Automated pipelines, model registry, basic monitoring
- Level 3: Feature store, automated retraining, A/B testing, drift detection, CI/CD for models

