Here’s a clear explanation of Retrieval-Augmented Generation (RAG) architecture, broken down by components, data flow, and key design choices.
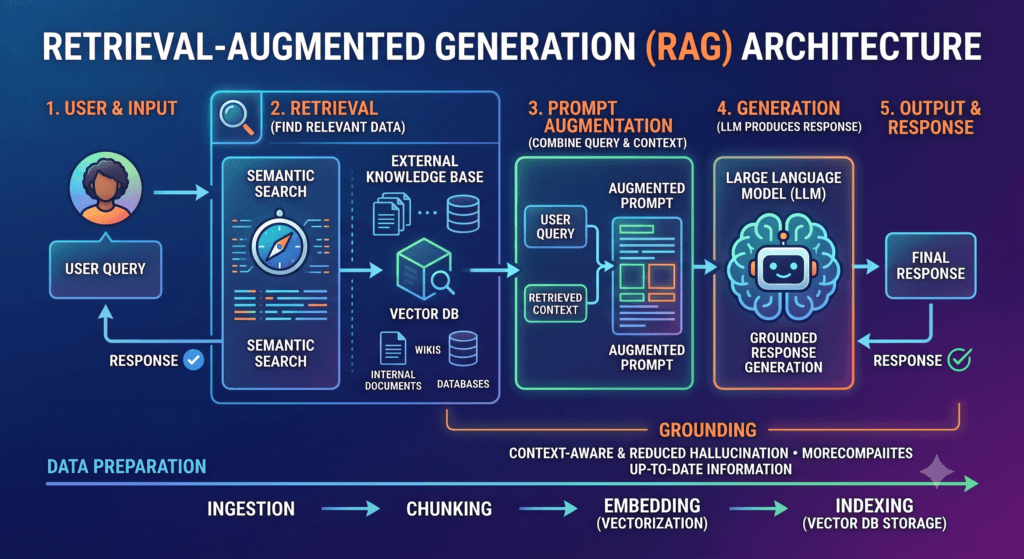
What is RAG?
RAG combines information retrieval with generative LLMs to produce grounded, accurate, and up-to-date responses. It solves two main LLM problems:
- Hallucination (making up facts)
- Stale knowledge (training data cut-off date)
High-Level Architecture
text
┌─────────────────────────────────────────────────────────────────────┐
│ QUERY PIPELINE │
└─────────────────────────────────────────────────────────────────────┘
User Query ──► [Embedding Model] ──► [Vector DB] ──► Top-K Chunks
│ ▲
│ │
└────────────────────► [Prompt Constructor] ◄── [System Prompt]
│
▼
[LLM Generation]
│
▼
Final Answer
┌─────────────────────────────────────────────────────────────────────┐
│ INDEXING PIPELINE (Offline) │
└─────────────────────────────────────────────────────────────────────┘
Documents ──► [Chunking] ──► [Embedding Model] ──► [Vector DB]Component Details
1. Indexing Pipeline (Pre-processing, run once or periodically)
| Component | Function | Example |
|---|---|---|
| Document Loader | Ingests PDFs, HTML, Confluence, Zendesk, etc. | UnstructuredIO, LangChain loaders |
| Chunking | Splits documents into smaller pieces (e.g., 512 tokens) | RecursiveCharacterTextSplitter, semantic chunking |
| Embedding Model | Converts text chunks into dense vectors | text-embedding-3-small, BAAI/bge-large-en |
| Vector Database | Stores + indexes embeddings for similarity search | Pinecone, Weaviate, pgvector, FAISS |
| Metadata Store | Stores source, date, page number for each chunk | JSON field in vector DB or separate DB |
2. Query Pipeline (Runtime)
| Component | Function |
|---|---|
| Query Embedding | Convert user query to vector (same model as indexing) |
| Similarity Search | Find top-K chunks (cosine / dot product / Euclidean) |
| Re-ranking (optional) | Reorder chunks with cross-encoder for higher precision |
| Prompt Construction | Inject retrieved chunks into prompt template |
| LLM Generation | Generate answer conditioned on query + chunks |
| Citation/Attribution | Return source references with answer |
Data Flow Example
User query: “What is your refund policy for electronics?”
Step 1 – Retrieve:
- Embed query → search vector DB → top 3 chunks:
- “Electronics can be returned within 30 days if unopened.” (source: policy.pdf, p.4)
- “Opened electronics are subject to 15% restocking fee.” (source: policy.pdf, p.5)
- “Defective electronics: free replacement within 1 year.” (source: warranty.pdf, p.2)
Step 2 – Generate prompt:
text
System: Answer using only the context below. Cite sources. Context: [1] Electronics can be returned within 30 days if unopened. (policy.pdf p.4) [2] Opened electronics are subject to 15% restocking fee. (policy.pdf p.5) [3] Defective electronics: free replacement within 1 year. (warranty.pdf p.2) User: What is your refund policy for electronics?
Step 3 – LLM output:
“Our refund policy for electronics depends on condition: unopened items can be returned within 30 days (policy.pdf p.4). Opened items have a 15% restocking fee (policy.pdf p.5). Defective items are replaced for free within 1 year (warranty.pdf p.2).”
Key Design Variations
| Variation | Description | Use Case |
|---|---|---|
| Naive RAG | Retrieve → generate once | Simple Q&A |
| RAG with Fusion | Query expansion + multiple retrieval strategies | High recall needs |
| Self-RAG | LLM decides whether to retrieve or not | Reducing unnecessary retrieval |
| Corrective RAG | Check retrieval quality; re-retrieve if low | Hallucination-critical apps |
| Agentic RAG | LLM uses retrieval as a tool, can search multiple times | Complex multi-step questions |
Advanced Components (Optional)
- HyDE – Generate hypothetical answer first, then retrieve similar documents
- Re-ranking – Cross-encoder (e.g.,
cross-encoder/ms-marco-MiniLM-L-6-v2) to reorder chunks - Context Compression – Summarize or extract only relevant sentences from long chunks
- Hybrid Search – Combine vector search + keyword (BM25) for better precision on rare terms
Common Failure Modes & Mitigations
| Problem | Mitigation |
|---|---|
| Low relevance chunks | Re-ranking, better chunk sizing, hybrid search |
| Missing context | Query rewriting, multi-step retrieval, feedback loop |
| LLM ignores context | Prompt constraints, instruction fine-tuning |
| High latency | Cache embeddings, smaller LLM, semantic caching |
| Outdated indexed docs | Incremental indexing, freshness monitoring |
Where RAG Fits in Customer Support
In your GenAI support solution, RAG would be used to retrieve from:
- Product manuals – Troubleshooting steps
- Policy documents – Refund, shipping, warranty
- Past tickets – Similar resolved cases
- Internal wikis – Agent-only knowledge

