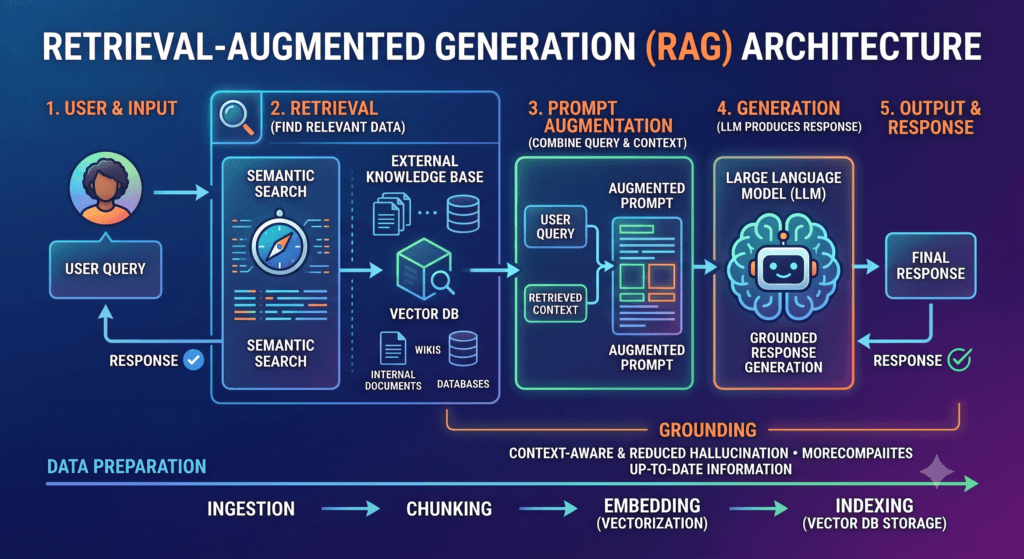
If you’re preparing for interviews on RAG (Retrieval-Augmented Generation) Architecture, interviewers often evaluate five areas:
- RAG fundamentals
- Architecture and components
- Vector databases and embeddings
- Advanced RAG techniques
- Production and scalability challenges
Below is a comprehensive interview guide with detailed answers.
1. What is RAG?
Answer
RAG (Retrieval-Augmented Generation) is an AI architecture that combines:
- Information Retrieval (searching external knowledge)
- Large Language Models (LLMs) (generating responses)
Instead of relying only on the knowledge stored in model parameters, the model retrieves relevant information from external sources and uses it as context to generate answers.
Flow
User Query
↓
Embedding Model
↓
Vector Search
↓
Relevant Documents Retrieved
↓
Prompt Construction
↓
LLM
↓
Final AnswerBenefits
- Reduces hallucinations
- Uses latest information
- Domain-specific knowledge
- No need to retrain LLM frequently
2. Why is RAG needed?
Answer
LLMs have several limitations:
Knowledge Cutoff
Example:
GPT trained until 2024
Question about 2026 events
Cannot answer accuratelyHallucinations
Models may generate convincing but incorrect information.
Domain-Specific Data
Company documents:
- Internal policies
- Contracts
- Product manuals
cannot be included in base training.
RAG solves these by retrieving real documents at inference time.
3. Explain RAG Architecture End-to-End
Answer
Main components:
Data Source
↓
Document Loader
↓
Chunking
↓
Embedding Model
↓
Vector Database
↓
User Query
↓
Query Embedding
↓
Similarity Search
↓
Top-K Retrieval
↓
Prompt Augmentation
↓
LLM
↓
Answer4. What are the major components of RAG?
Answer
1. Data Source
Examples:
- PDFs
- Word documents
- Databases
- Websites
- APIs
2. Document Loader
Extracts text.
Examples:
- LangChain loaders
- LlamaIndex readers
3. Chunking
Breaks large documents into smaller pieces.
Example:
100-page PDF
→ 1000 chunks4. Embedding Model
Converts text into vectors.
Example:
"The sky is blue"
↓
[0.23, -0.11, 0.44 ...]5. Vector Database
Stores embeddings.
Examples:
- Pinecone
- Weaviate
- Milvus
- Qdrant
- Chroma
6. Retriever
Finds relevant chunks.
7. Prompt Builder
Combines:
Question
+
Retrieved Context8. LLM
Generates final answer.
5. What is Embedding?
Answer
Embedding is a dense numerical representation of text.
Example:
Dog
Cat
PuppyThese words have similar vectors because they are semantically related.
Purpose
Convert text into mathematical space where similarity can be measured.
6. What are Vector Embeddings?
Answer
A vector embedding is:
Text → High-dimensional vectorExample:
"AI is transforming healthcare"
↓
[0.45, -0.12, 0.88, ...]Dimension may be:
- 384
- 768
- 1024
- 1536
- 3072
7. Why can’t we use keyword search instead of vector search?
Answer
Keyword search finds exact words.
Example:
Query:
carDocument:
automobileKeyword search fails.
Vector search understands semantic similarity.
8. What is Semantic Search?
Answer
Semantic search finds meaning rather than exact keywords.
Example:
Query:
How do I reset my password?Document:
Steps to change account credentialsSemantic search can match them.
9. What is Chunking?
Answer
Chunking is splitting large documents into smaller pieces.
Example:
100-page manual
↓
500-word chunksReason:
LLMs have context limits.
10. Why is Chunking Important?
Answer
Without chunking:
Entire PDF → One embeddingRetrieval quality becomes poor.
With chunking:
Each section searchableBetter precision.
11. Types of Chunking
Answer
Fixed Chunking
500 tokens eachRecursive Chunking
Preserves paragraph boundaries.
Semantic Chunking
Splits based on meaning changes.
Sentence Chunking
Split by sentence.
Sliding Window Chunking
Overlap between chunks.
Example:
Chunk1: 1-500
Chunk2: 450-95012. What is Chunk Overlap?
Answer
Overlap preserves context across chunks.
Example:
Chunk1: 1-500
Chunk2: 450-950Overlap = 50 tokens.
Benefit:
Prevents information loss.
13. What is a Vector Database?
Answer
A database optimized for storing and searching embeddings.
Capabilities:
- Similarity search
- Metadata filtering
- Fast retrieval
14. Difference Between SQL DB and Vector DB
| SQL DB | Vector DB |
|---|---|
| Exact matching | Similarity matching |
| Structured data | Embeddings |
| WHERE clause | Nearest neighbor search |
15. What is Similarity Search?
Answer
Finding vectors closest to query vector.
Most common metrics:
Cosine Similarity
Measures angle.
Euclidean Distance
Measures geometric distance.
d=∑i=1n(xi−yi)2
Dot Product
A · B16. What is Top-K Retrieval?
Answer
Retriever returns K most relevant chunks.
Example:
Top 3 chunks
Top 5 chunks
Top 10 chunksK is tunable.
17. What Happens After Retrieval?
Answer
Retrieved chunks are inserted into prompt.
Example:
Context:
[Chunk1]
[Chunk2]
Question:
What is RAG?Then sent to LLM.
18. What is Prompt Augmentation?
Answer
Adding retrieved documents into the prompt.
Example:
Question
+
Retrieved Context
+
Instructions19. What is Hallucination?
Answer
LLM generates unsupported facts.
Example:
Inventing policy details not present in documents.
RAG reduces hallucination because answers are grounded in retrieved evidence.
20. What is Grounding?
Answer
Generating answers strictly based on retrieved content.
21. What is Retrieval Precision?
Answer
Percentage of retrieved documents that are relevant.
Formula:
Precision=Total RetrievedRelevant Retrieved
22. What is Retrieval Recall?
Answer
Ability to retrieve all relevant documents.
Recall=Total RelevantRelevant Retrieved
23. What is ANN Search?
Answer
Approximate Nearest Neighbor Search.
Used because exact search is expensive for millions of vectors.
Popular algorithms:
- HNSW
- IVF
- PQ
24. What is HNSW?
Answer
Hierarchical Navigable Small World graph.
Most popular ANN algorithm.
Benefits:
- Fast retrieval
- High recall
- Scalable
25. What is Metadata Filtering?
Answer
Search vectors plus metadata.
Example:
{
"department":"finance",
"year":"2025"
}Retrieve only finance documents.
26. What is Hybrid Search?
Answer
Combines:
Vector Search
+
Keyword SearchBenefits:
- Semantic understanding
- Exact keyword matching
27. What is Re-ranking?
Answer
Second-stage ranking.
Flow:
Top 100 retrieved
↓
Cross Encoder
↓
Top 10 finalImproves relevance significantly.
28. What is Cross Encoder?
Answer
Model evaluates:
Query + DocumentTogether.
More accurate than embeddings.
More expensive.
29. What is Query Expansion?
Answer
Expand user query.
Example:
AI
→ Artificial Intelligence
→ Machine Learning
→ Deep LearningImproves retrieval.
30. What is Multi-Query Retrieval?
Answer
Generate multiple reformulations.
Example:
Query1
Query2
Query3Search all and merge results.
31. What is Parent-Child Retrieval?
Answer
Store:
Small chunksRetrieve:
Larger parent documentsImproves context quality.
32. What is Context Window?
Answer
Maximum tokens an LLM can process.
Example:
- 8K
- 32K
- 128K
- 1M+
33. What is Context Compression?
Answer
Reducing retrieved content size before sending to LLM.
Methods:
- Summarization
- Re-ranking
- Filtering
34. What is Advanced RAG?
Answer
Enhanced retrieval pipeline.
Examples:
- Hybrid Search
- Agentic RAG
- Graph RAG
- Multi-hop RAG
- Self-RAG
- Corrective RAG
35. What is Graph RAG?
Answer
Uses knowledge graphs instead of only vectors.
Structure:
Entity
↓
Relationship
↓
EntityBetter for connected knowledge.
36. What is Agentic RAG?
Answer
Agent decides:
- What to retrieve
- Which tool to use
- Whether retrieval is needed
More autonomous than traditional RAG.
37. What is Self-RAG?
Answer
Model evaluates its own retrieval quality and can retrieve again if needed.
38. What is Corrective RAG (CRAG)?
Answer
Detects poor retrieval and corrects it using alternative searches.
39. What is Multi-Hop Retrieval?
Answer
Requires multiple retrieval steps.
Example:
CEO of company that acquired X?Need intermediate reasoning.
40. What are Common Production Challenges?
Answer
Poor Chunking
Bad retrieval quality.
Embedding Drift
Changing embedding models causes mismatch.
Latency
Multiple retrieval stages increase response time.
Cost
LLM + vector DB costs.
Hallucinations
Still possible if retrieval fails.
41. How Do You Evaluate a RAG System?
Answer
Metrics:
- Precision
- Recall
- MRR
- NDCG
- Faithfulness
- Answer Relevancy
- Context Precision
- Context Recall
Frameworks:
- Ragas
- DeepEval
- TruLens
42. Difference Between Fine-Tuning and RAG?
| Fine-Tuning | RAG |
|---|---|
| Changes model weights | Uses external knowledge |
| Expensive | Cheaper |
| Static knowledge | Dynamic knowledge |
| Retraining needed | Update documents only |
43. When Should You Use RAG Instead of Fine-Tuning?
Answer
Use RAG when:
- Knowledge changes frequently
- Private documents
- Latest information needed
- Large document repositories
44. Can RAG and Fine-Tuning Be Used Together?
Answer
Yes.
Common enterprise architecture:
Fine-Tuned LLM
+
RAG
+
ToolsFine-tuning improves behavior; RAG provides knowledge.
45. Design a Production-Grade RAG Architecture
Answer
Documents
↓
ETL Pipeline
↓
Chunking
↓
Embedding Service
↓
Vector DB
↓
User Query
↓
Query Rewriting
↓
Hybrid Retrieval
↓
Re-ranking
↓
Context Compression
↓
LLM
↓
Guardrails
↓
ResponseMost Important Interview Questions (Frequently Asked by FAANG/Product Companies)
- Explain end-to-end RAG architecture.
- Why do we need chunking?
- How do you choose chunk size?
- What embedding model would you use and why?
- Difference between vector search and keyword search.
- What is hybrid search?
- What is re-ranking?
- How would you reduce hallucinations in RAG?
- How do you evaluate retrieval quality?
- What is HNSW?
- What is Graph RAG?
- What is Agentic RAG?
- How would you scale a RAG system to 100M documents?
- Fine-tuning vs RAG?
- How would you troubleshoot poor retrieval results?
- How would you reduce latency in a RAG pipeline?
- Explain metadata filtering.
- What happens when embeddings are regenerated?
- How would you build a multilingual RAG system?
- Design a complete enterprise RAG platform from scratch.
These 45 questions cover roughly 90–95% of what is typically asked in RAG architecture interviews ranging from mid-level ML/GenAI engineers to senior AI architects.

