IIn the early days of generative AI acceleration, RAG — Retrieval-Augmented Generation — was often portrayed as a simple add-on: embed text, store vectors, and send those vectors to a large language model (LLM) for a response. That pipeline worked fine for prototypes and demos — the kind of “chat with your documents” toy bots that proliferate across tutorials and blog posts.

But in 2026, production-grade RAG is fundamentally different. It’s no longer a trivial component; it’s become a full-blown system architecture that underpins how AI products deliver trustworthy and useful answers at scale.
At its core, modern RAG still includes retrieval and generation, but how those parts are implemented, orchestrated, and operationalized reflects the real challenges of production AI — especially accuracy, freshness, safety, and observability.
Why the Classic Pipeline Isn’t Enough
Most online examples still show:
- User query → Embedding → Vector DB → LLM → Response
This is fine for demos, but in real applications it fails in many ways:
- It doesn’t prevent the model from seeing wrong or stale data.
- It can’t enforce security or privacy rules.
- It lacks mechanisms to monitor or measure performance.
Production teams now thinking beyond “just embeddings” — they treat the whole retrieval flow as an operating system for truth and context.
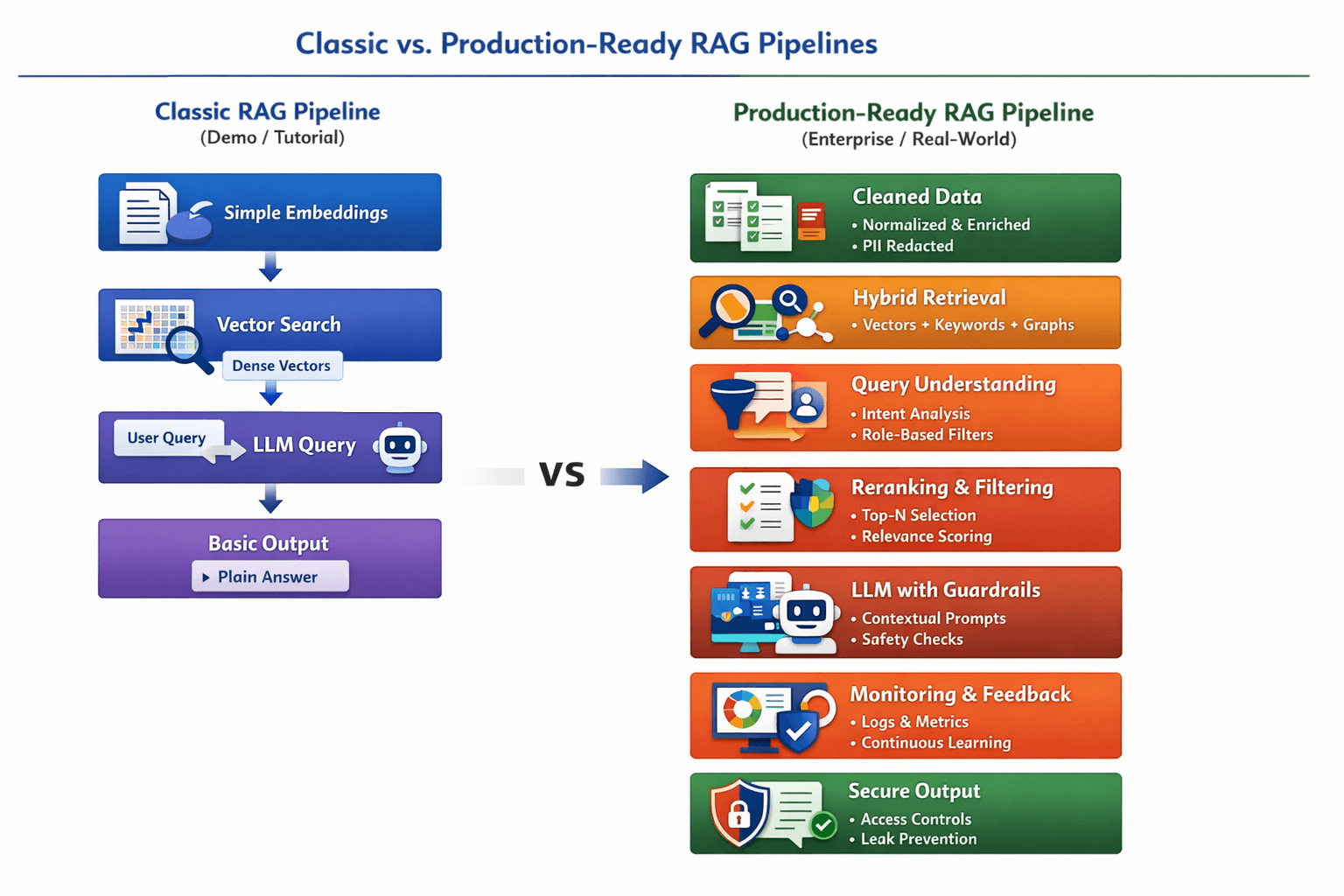
What a Modern Production RAG Stack Looks Like
Here’s how teams are designing RAG systems in the real world:
1. Data as a First-Class Citizen
Before retrieval even happens, data must be:
- Cleaned and normalized across formats (PDFs, tables, code).
- Deduplicated and enriched with metadata like ownership, timestamps, and sensitivity.
- Redacted for PII and secrets.
Without this, retrieval is garbage-in, garbage-out.
2. Hybrid Retrieval, Not Just Vectors
Instead of only dense vector search, modern systems combine:
- Dense semantic search for contextual meaning.
- Sparse keyword search for exact matches.
- Graph or entity signals to capture relationships.
These are fused and ranked to increase relevance.
3. Query Understanding Is the Hidden Superpower
Smart systems don’t just search for tokens — they interpret user intent, rewrite queries for clarity, and apply filters based on:
- User role and permissions
- Time or document type
- Conversational context prior to retrieval
This intent-aware retrieval ensures the right evidence surfaces for every request.
4. Reranking as a Quality Gate
Top-K retrieval alone isn’t sufficient. After retrieving many candidates, a reranker selects the best subset for the LLM — often using advanced scoring models.
This step is critical to avoid “confidently wrong” responses and improve factual grounding.
5. Guardrails and Safety Layers
Production RAG systems incorporate:
- Access control to enforce permissions
- Prompt-injection detectors
- Leak prevention mechanisms
These aren’t optional — they protect the system from misuse and data leaks.
6. Observability, Ops, and Continuous Learning
A mature RAG pipeline treats itself as a product with:
- Tracing: query → chunks → answer
- Metrics: latency, recall, rerank scores, token use
- A/B tests and feedback loops to refine retrieval
If you can’t measure it, you can’t improve it.
From Feature to Foundation
What used to be a “feature” in demos is now a foundation for truth in AI products. Modern RAG is less about “which vector database should I use?” and more about:
- Keeping the model honest
- Retrieving the right evidence
- Providing systems with safety and observability
The gap between prototype and production isn’t just tooling — it’s systems thinking.
As developers, data engineers, and AI architects embrace these patterns, RAG systems are moving closer to intelligent infrastructure — one that scales, evolves, and delivers reliable knowledge at enterprise speed.
1. Classic vs. Production RAG Architectures
| Feature / Layer | Classic RAG (Demos / Tutorials) | Production RAG (Enterprise / Real-World) |
|---|---|---|
| Data Handling | Simple embeddings from raw text | Cleaned, normalized, deduplicated, PII-redacted, enriched with metadata |
| Retrieval Method | Dense vector search only | Hybrid search: dense vectors + sparse keywords + graph/entity signals |
| Query Understanding | Pass-through user query | Intent-aware query rewriting, context expansion, role & permission filters |
| Reranking | Top-K retrieval returned directly | Reranker models filter top candidates for accuracy and relevance |
| LLM Integration | Plain prompt with retrieved chunks | Prompt engineering with context, safety layers, and response validation |
| Security & Privacy | None | Access control, prompt-injection prevention, sensitive data masking |
| Observability | Minimal / none | Full metrics, logging, traceability, and continuous feedback loops |
| Maintenance | Manual updates of data | Automated ingestion, periodic re-indexing, monitoring for stale data |
| Scalability | Small datasets, low concurrency | High-throughput, distributed databases, latency-optimized pipelines |
| Reliability | Low; prone to hallucinations | High; includes guardrails, retriever validation, and fallback strategies |
✅ Key takeaway: Classic RAG is sufficient for demos, but production RAG is a system architecture that integrates data engineering, security, and operational monitoring to reliably serve real users.

